据9to5Google 报道,谷歌准备关闭 Android 上的独立街景 App,不过谷歌地图上的街景服务功能仍存在。

图片来自 Google
在最新的独立街景 App 更新版本2.0.0.484371618中,Google 被发现准备关闭街景 App 的通知。这些通知在 App 中尚不可见,但通过反编译启用它们后,发现了有关准备关闭街景 App 的通知。Google 发言人随后向 The Verge 证实,有关街景 App 将在2023年3月中止服务。Google 并鼓励用户切换到 Google 地图或街景工作室。
Google 的街景能够让用户轻松360度全方位观察地球上几乎特定街道的方法,非常适合了解下一个旅行目的地或只是在家中舒适地探索世界。虽然 Google 地图 App 程序长期以来提供进入街景的简单方法,但在 Android 和 iOS 上也有专门的街景应用 App。
这个独立的 App 主要服务于两个不同的人群,首先是想要深入浏览街景的人和想要贡献360度图像的人。考虑到 Google 地图使用的用户更多,并且 Google 为贡献者提供独立的街景工作室 App,关闭街景 App 也是意料之中。
1998年,腾讯在“中国硅谷”深圳扎根,一步步成为互联网巨头。
同时,在美国的硅谷,一家影响全球的互联网企业也生根发芽。
它被公认为全球最大的搜索引擎公司,它的AlphaGo惊艳世人,开启深度研究AI的时代。
今天的主人公就是来自美国的谷歌Google。
从1998年的在线搜索,到今天试图“称霸全球”的科技公司,谷歌有着怎样的发展史?

开发搜索引擎
最最开始,谷歌只是佩奇的一个搜索项目PageRank,佩奇也不是那个“佩奇”,而是拉里·佩奇。
1996年,在斯坦福校园里,他结识了同为计算机专业的学长谢尔盖·布林。
彼时互联网已然在美国兴起,很多人利用互联网去购物、去认识朋友。
但佩奇并不在乎利用互联网去做什么,他要去了解互联网最真实的样子。
虽然佩奇对布林有过这样的评价:“我觉得他很讨厌。”
但这并不妨碍,他们对计算机有着同样独特的追求,在他们怪异性格的深处,同样藏着强大的头脑。
Google就在他们对论文研究的过程中,偶然诞生了。
佩奇和布林创建了PageRank算法,根据链接行为对搜索结果进行排名。
这个算法很快便在斯坦福校园内流传,两年后,两人以数学术语10的100次方“googol”重新命名。
1998年,Google在线搜索引擎正式上线。

同年8月两人在加利福尼亚州建立公司,并且拿到10万美元的天使投资。
佩奇和布林在计算机科学上有着聪明的头脑,但对于管理一家公司,他们更倾向于交给职业经理人去负责。
2001年,两人聘请埃里克·施密特出任Google首席执行官。他不仅有着技术背景,也有丰富的管理经验。
搜索爆火,业务扩展
尽管新世纪之初时,谷歌也仅仅有三四年的历史,但它惊人的发展速度让人无法忽视。
2000年,Google每天的搜索请求就已达到1800万次,成为当下最火热的搜索引擎。
当时在互联网中占绝对地位的雅虎也曾使用谷歌的搜索引擎,后来在2002年夏天,雅虎试图收购谷歌,但最终被谷歌拒绝。
雅虎对谷歌的收购计划,让谷歌明白,真正强大的企业,不应该“一条腿走路”。
这年年底,谷歌推出新闻业务。利用Google搜索,改变新闻传播的方式,将数字媒体带进人们的生活。
随着谷歌的发展,无论是企业员工还是互联网同行,人们都在期待着谷歌的行动。2004年,谷歌在纳斯达克上市。
上市之后,谷歌就不再是一家私有企业,它要考虑的事情更多:业务板块、企业文化等。
2004年,谷歌上线Gmail邮件,它能提供1GB储存空间以及高级搜索功能,做到了其他邮件不能做的事。
接着它收购锁眼,该公司的技术顺理应当的进入谷歌。第二年,谷歌地图正式上线,提供包括详细卫星照片的各种地图服务。
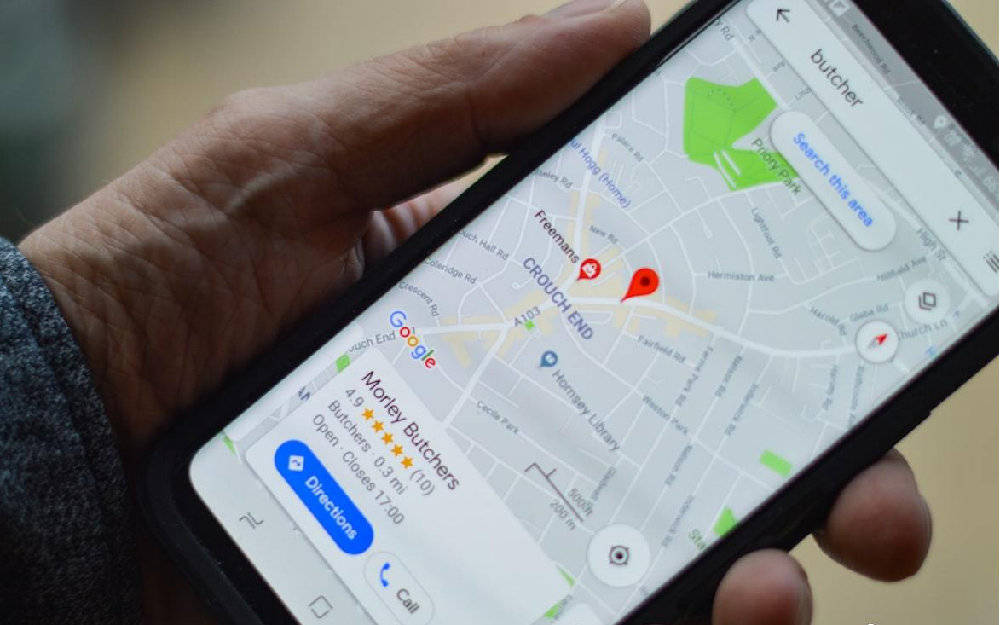
2006年收购YouTube,将视频业务纳入麾下,YouTube也凭借谷歌的名声获得大量用户。
第二年,谷歌收购网络公司DoubleClick,使得公司的广告业务更上一层楼。
这些年来,互联网瞬息万变,但它发现,网络的入口“浏览器”的变化却并不明显。
谷歌,就要改变这个现状。2008年,推出Chrome浏览器,并且创新添加了“新标签页”功能。
随着移动互联网时代的到来,谷歌也开始进入手机行业,收购Android操作系统,推出智能手机等。
2015年,“伞形公司”Alphabet成立,谷歌成为其旗下子公司。
从此,“谷歌”的业务逐渐完善:互联网搜索、云计算、广告技术等。

地位攀升,野心不止
谷歌有着这样的使命:整合全球信息,使人人皆可访问并从中受益。
公司使命推动着谷歌的全球布局,早在2005年的时候,它就进入中国,设立研发中心。
2008年,谷歌正式打开我国市场,然而只存在两年的时间便黯然退场。
因为我们看到它在我国布局过程中涌动着的“野心”,那是涉及国家安全的野心。
从2010年起,我国便不再使用谷歌搜索、谷歌地图等。
不过,谷歌与我国的技术合作仍在进行,成立复旦大学-谷歌科技创新实验室。
如今,谷歌已经布局全球200多个国家,支持100多种语言。
它的确是全球最大的搜索引擎,但同时它也是各国反垄断的对象。
过去,Google带我们进入搜索的世界;但现在它更像是源头,孕育着独立个体,共同组成“Alphabet”,创造新的历史。

研究显示使用谷歌会导致人们对自己的智商有错误认识
凤凰网科技讯 北京时间10月30日消息,搜索引擎是了不起的工具,不过,通过敲几下键盘就能找到关心问题的答案,会使用户高估自己的聪明程度。美国德州大学的一项研究显示,对于经常使用谷歌搜索服务的用户,即使不使用它,也会对自己提供正确答案的能力更有信心。
研究人员对被试者进行了通识题测试,被试者可以靠自己的回忆,也可以借助谷歌回答问题。使用搜索工具的被试者不仅回答了更多问题,对自己能回答其他问题也更有信心。
尽管答题时使用了谷歌,部分被试者之后认为自己靠记忆回答了问题。论文作者、德州大学麦康库姆斯商学院营销学教授艾德里安·瓦尔德(Adrian Ward)说,“不断使用知识时,内部和外部知识之间的界线会模糊、消褪,人们就会误把互联网的知识当作自己的知识。”
瓦尔德的发现其实属于达克效应。达克效应是一种心理学现象,指虽然人们对某一领域了解有限,却高估自己在该领域的知识或能力,原因是他们不知道自己存在不足,就认为自己不存在不足。正如查尔斯·达尔文(Charles Darwin)所说的那样,“无知比知识更容易让人自信。”
瓦尔德表示,尽管自文字出现以来人们依靠图书和其他渠道获取知识,搜索服务的速度和信息的全面,会使人们把搜索得来的信息与大脑记忆的信息混为一谈。他说,当可以随时使用搜索服务后,人们“就不会费力记忆信息了,我们不会再锻炼记忆力”。
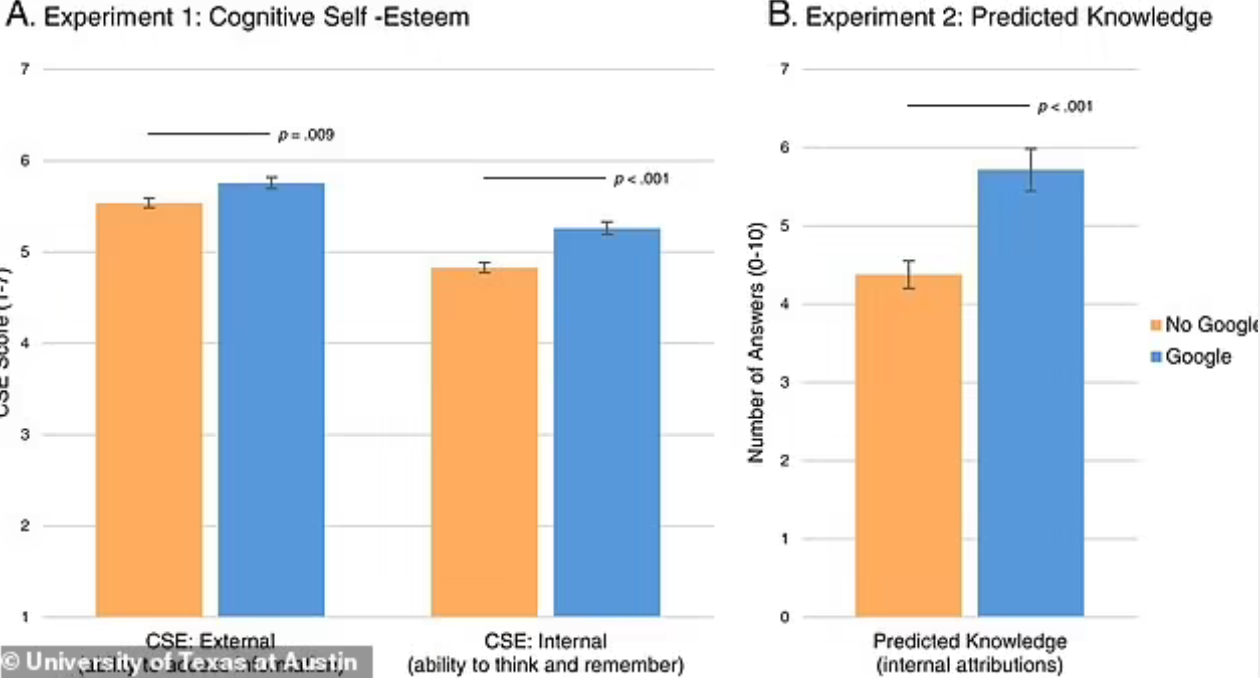
图表显示,即使不使用谷歌,经常使用谷歌的人也相信自己能正确回答问题
为了研究这一现象,瓦尔德让被试者通过记忆或借助搜索服务回答10个通识问题。被试者还需要回答对记忆信息或使用搜索工具获取信息能力的自信程度
让人感到意外的是,与依靠自己记忆力的被试者相比,借助谷歌的被试者能回答出更多问题。他们不但对自己通过外部渠道获取信息的能力更有自信,对自己的记忆力也更有自信。
然后瓦尔德告知被试者还需要参加第二轮测试,而且不能借助谷歌,并要求他们猜测自己能正确回答几个问题。对于在第一轮测试中借助谷歌搜索答案的被试者来说,即使不能使用搜索服务了,也相信自己大脑记忆有更多信息。
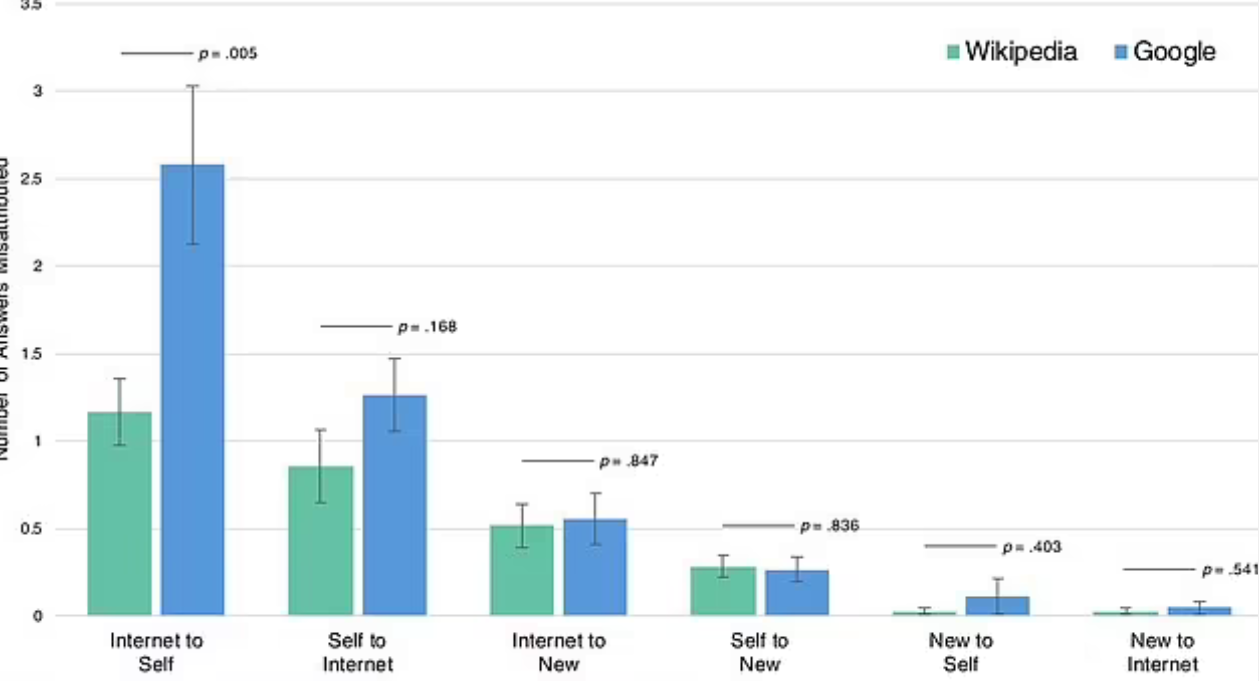
在被问到如何回答某个问题时,许多曾借助谷歌的人,都错误地认为依靠自己的记忆回答了问题
瓦尔德在发表在《美国国家科学院院刊》上的论文中写道,“借助谷歌回答通识问题,会人为放大人们对自己记忆和处理信息能力的自信,导致他们对不借助互联网时自己的知识不恰当地乐观。当信息‘唾手可得’时,我们可能错误地认为记住了它们”。
谷歌搜索服务的速度,也是让用户“谜之自信”的一个原因。在随后的一轮测试中,瓦尔德向被试者提供了一个特别版本的谷歌:延迟25秒显示搜索结果。他发现,使用低速版谷歌的被试者,对自己的内部知识不再“谜之自信”,对在未来测试中的表现不再有过高期望。

对自己掌握信息的过度自信,会让人们做出不恰当的健康和金融决策
瓦尔德发现,“互联网能无缝地提供信息,与人们自身的认知过程相吻合,它的贡献很容易被忽略。其结果就是,人们认识不到自己知识的不足,也意识不到自己借助了互联网。借助谷歌,会让人们把互联网的知识误认为是自己的知识。”
谷歌并非是互联网上唯一的信息来源,但其他服务似乎不会使人们“谜之自信”。在另一次测试中,瓦尔德要求参与者借助谷歌或维基百科回答50个问题
被试者会看到70个问题——其中包括50道已经回答过的问题和20道新题,对于每道题,被试者需要回答是否借助互联网或依靠自己的记忆曾经回答过这道题目,或者这是一道新题。瓦尔德发现,在确定信息来源方面,借助谷歌的被试者的表现要差得多。
特别是,在把网络信息误认为自己的信息方面,谷歌用户的表现要甚于维基百科。瓦尔德说,“我们发现,人们甚至忘记他们曾借助谷歌。”瓦尔德推测,维基百科提供有更多背景信息,人们需要更多时间消化这些信息,这可能有助于人们记起信息的来源。
对自己掌握信息的过度自信,会让人们做出不恰当的健康和金融决策,甚至会相信错误信息。
瓦尔德说,如果相信自己已经掌握了知识,学生就不会勤奋学习了。他建议,教育机构应当不再让学生记忆能借助谷歌获得的知识,“我们或许可以更高效地使用有限的认知资源。”(作者/霜叶)
在移动互联网时代,很多APP都开始封闭,流量不外传,比如腾讯的微信就限制搜索引擎索引他们的公众号文章,只能由微信自己搜索。今天有网友发现腾讯变了,微信放开了搜索限制,谷歌及必应可以搜索公众号文章,但百度不行。
据爆料,腾讯微信公众号官网的robots.txt被删了,这个文件是Robots协议(也称为爬虫协议、机器人协议等),全称是网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
刚刚验证了下,现在打开的话,robots.txt文件还在,内容似乎变了,多个规则都允许索引,看起来腾讯确实是放开限制了。
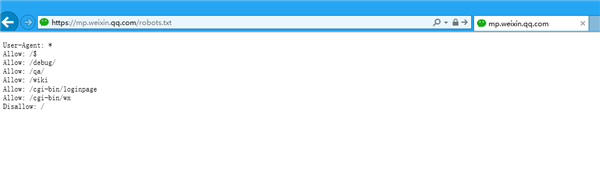
至于为什么改变,猜测跟工信部等多个部门要求互联网解除限制、屏蔽的要求有关,毕竟微信、支付宝、淘宝等都要互相开放,微信公众号文章搜索也不能由腾讯自己的搜索独占。
对广大网民来说,互联网巨头一步步放开限制当然是好事,有竞争才有进步,而不是每个平台都把用户及流量当做自己的自留地。




法国最大的搜索引擎 Qwant 启用新LOGO